- 1 pour vrai ou
- 0 pour faux
L’importance clé de la régression logistique:
- Les variables indépendantes ne doivent pas être multicollinéarité; s’il y a une relation, alors ce ne devrait être que très peu.
- L’ensemble de données pour la régression logistique doit être suffisamment grand pour obtenir de meilleurs résultats.
- Seuls ces attributs doivent être présents dans l’ensemble de données, ce qui a une certaine signification.
- Les variables indépendantes doivent être conformes à la consigner les cotes.
Pour construire le modèle du régression logistique, nous utilisons le scikit-learn bibliothèque. Le processus de la régression logistique en python est donné ci-dessous:
- Importez tous les packages requis pour la régression logistique et d’autres bibliothèques.
- Téléchargez l’ensemble de données.
- Comprendre les variables indépendantes du jeu de données et les variables dépendantes.
- Divisez l’ensemble de données en données d’entraînement et de test.
- Initialisez le modèle de régression logistique.
- Ajustez le modèle avec le jeu de données d’entraînement.
- Prédisez le modèle à l’aide des données de test et calculez la précision du modèle.
Problème: Les premières étapes consistent à collecter l’ensemble de données sur lequel nous voulons appliquer le Régression logistique. L’ensemble de données que nous allons utiliser ici est pour l’ensemble de données d’admission MS. Cet ensemble de données comporte quatre variables dont trois sont des variables indépendantes (GRE, GPA, work_experience) et une est une variable dépendante (admise). Cet ensemble de données indiquera si le candidat sera admis ou non dans une université prestigieuse en fonction de son GPA, de son GRE ou de son expérience de travail.
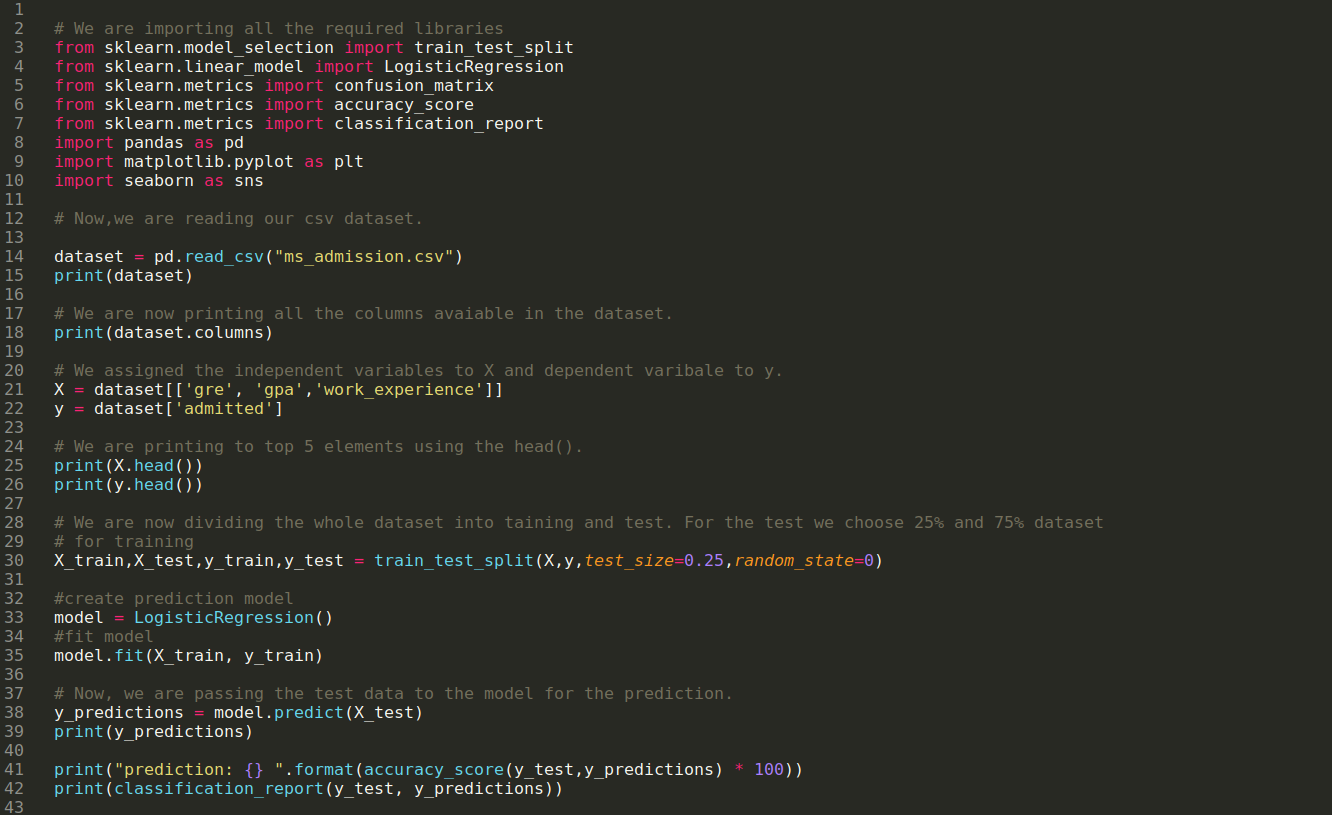
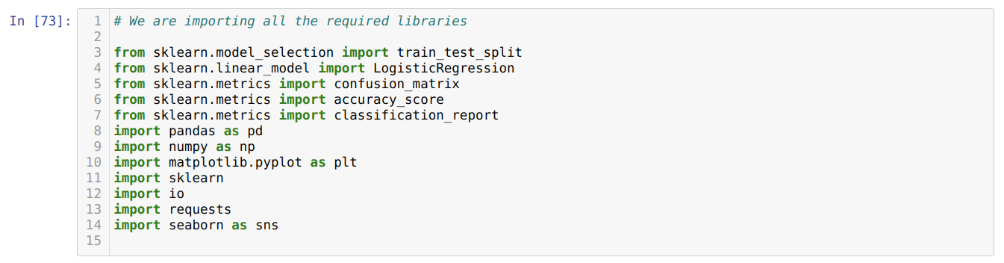
Étape 1: Nous importons toutes les bibliothèques requises dont nous avions besoin pour le programme python.
Étape 2: Maintenant, nous chargeons notre jeu de données d’admission ms en utilisant la fonction pandas read_csv.
![]()

Étape 3: L’ensemble de données ressemble à ci-dessous:
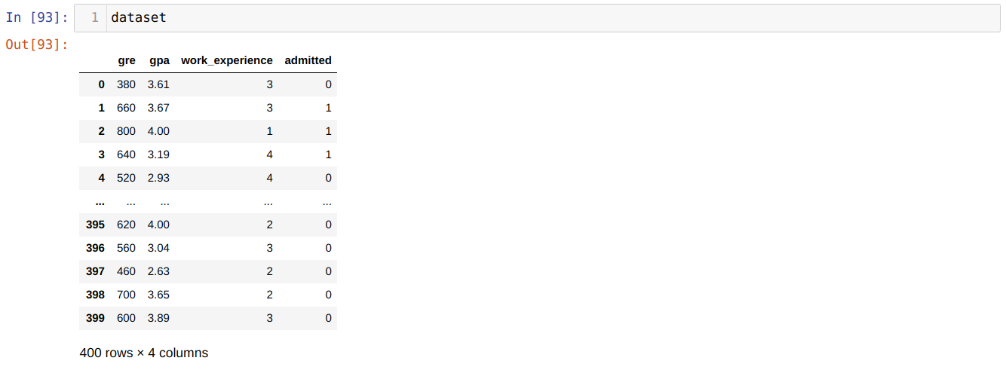
Étape 4: Nous vérifions toutes les colonnes disponibles dans l’ensemble de données, puis définissons toutes les variables indépendantes sur la variable X et les variables dépendantes sur y, comme indiqué dans la capture d’écran ci-dessous.

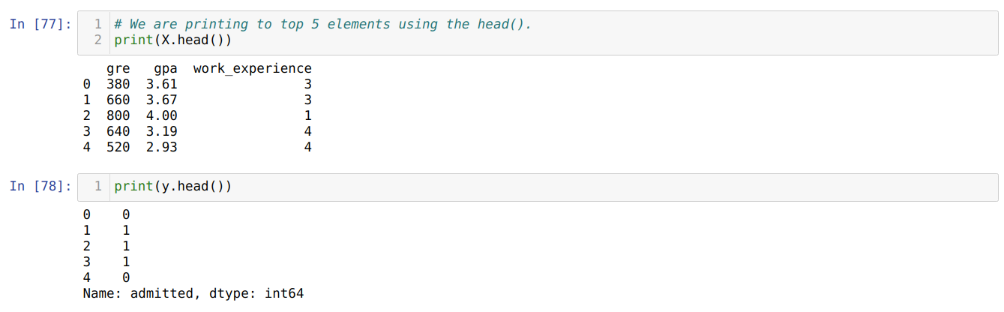
Étape 5: Après avoir défini les variables indépendantes sur X et la variable dépendante sur y, nous imprimons maintenant ici pour contre-vérifier X et y à l’aide de la fonction head pandas.
Étape 6: Maintenant, nous allons diviser l’ensemble de données en formation et test. Pour cela, nous utilisons la méthode train_test_split de sklearn. Nous avons donné 25% de l’ensemble de données au test et les 75% restants de l’ensemble de données à la formation.
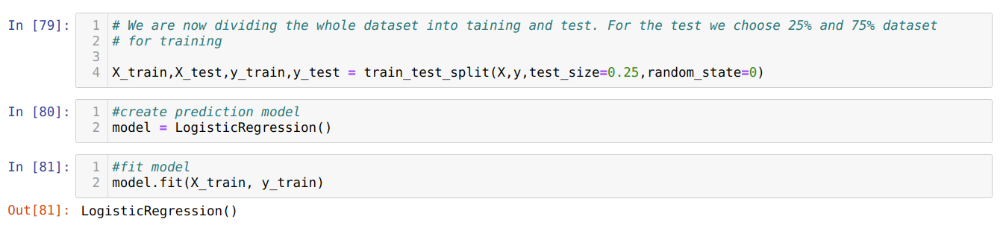
Étape 7: Maintenant, nous allons diviser l’ensemble de données en formation et test. Pour cela, nous utilisons la méthode train_test_split de sklearn. Nous avons donné 25% de l’ensemble de données au test et les 75% restants de l’ensemble de données à la formation.
Ensuite, nous créons le modèle de régression logistique et ajustons les données d’entraînement.
Étape 8: Maintenant, notre modèle est prêt pour la prédiction, donc nous transmettons maintenant les données de test (X_test) au modèle et obtenons les résultats. Les résultats montrent (y_predictions) que les valeurs 1 (admis) et 0 (non admis).

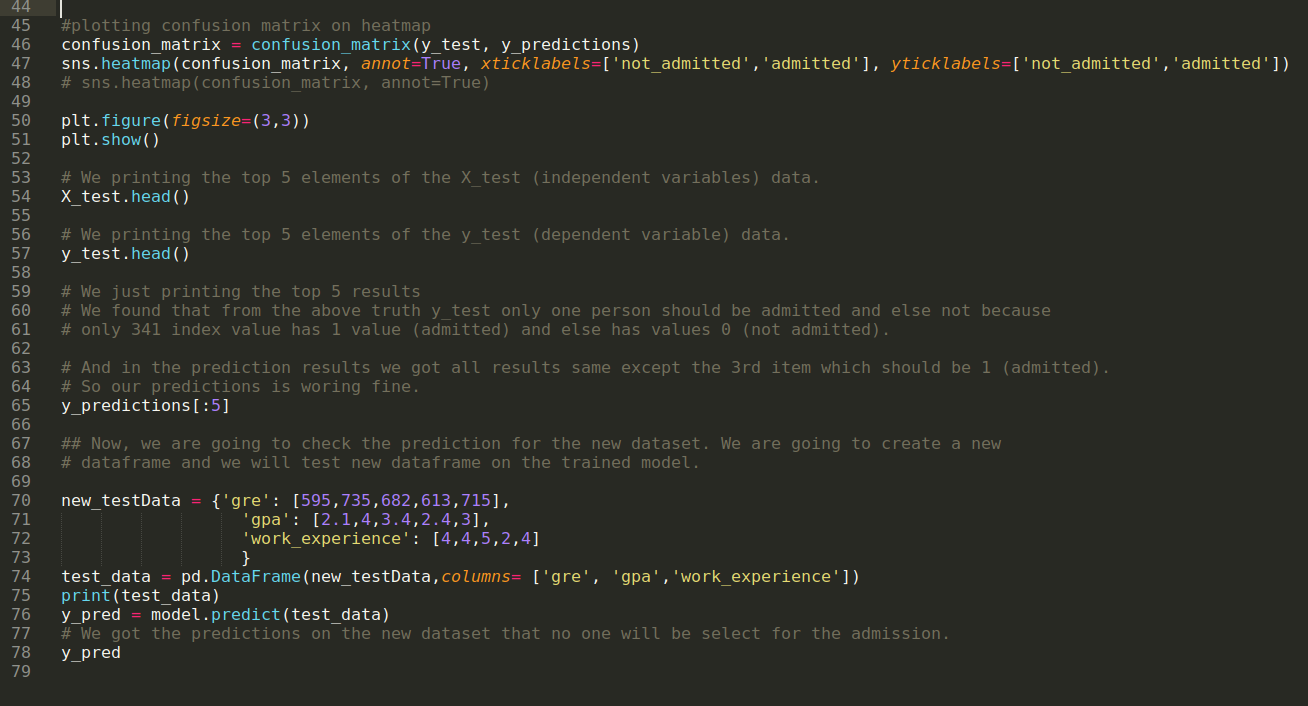
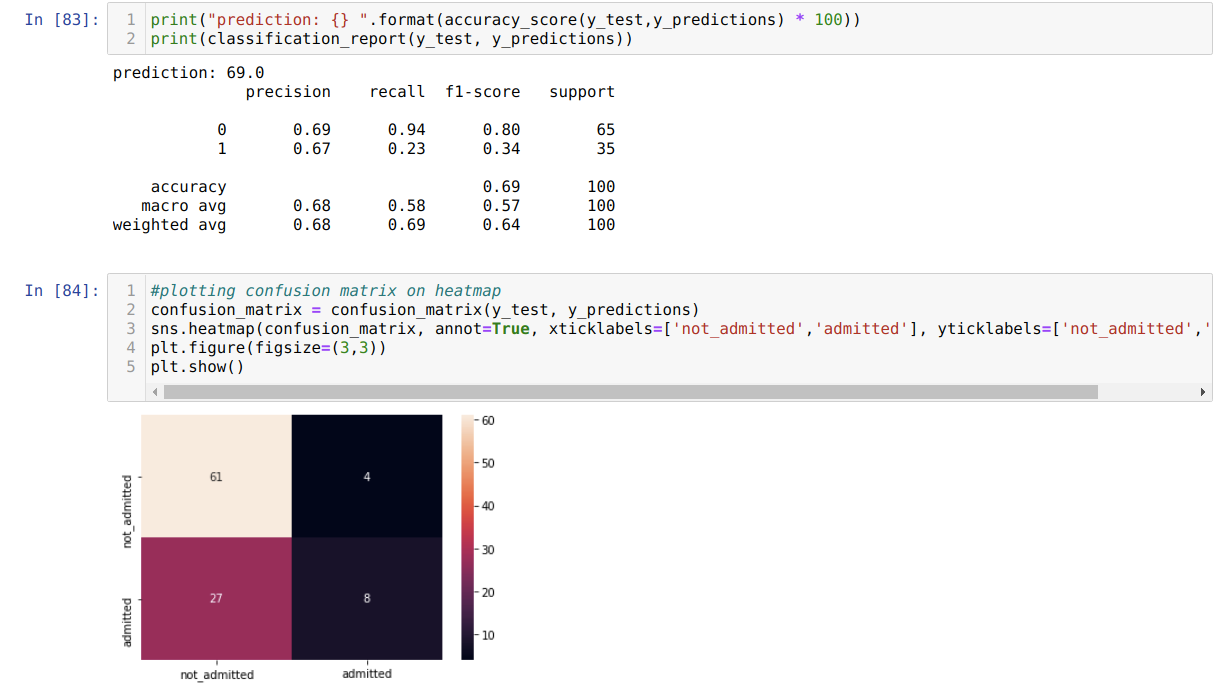
Étape 9: Maintenant, nous imprimons le rapport de classification et la matrice de confusion.
Le classement_report montre que le modèle peut prédire les résultats avec une précision de 69%.
La matrice de confusion montre le total des détails des données X_test comme suit:
TP = vrais positifs = 8
TN = vrais négatifs = 61
FP = faux positifs = 4
FN = faux négatifs = 27
Ainsi, la précision totale selon la confusion_matrix est:
Précision = (TP + TN) / Total = (8 + 61) / 100 = 0,69
Étape 10: Maintenant, nous allons contre-vérifier le résultat par impression. Donc, nous imprimons simplement les 5 premiers éléments du X_test et du y_test (valeur réelle réelle) en utilisant la fonction head pandas. Ensuite, nous imprimons également les 5 premiers résultats des prédictions comme indiqué ci-dessous:
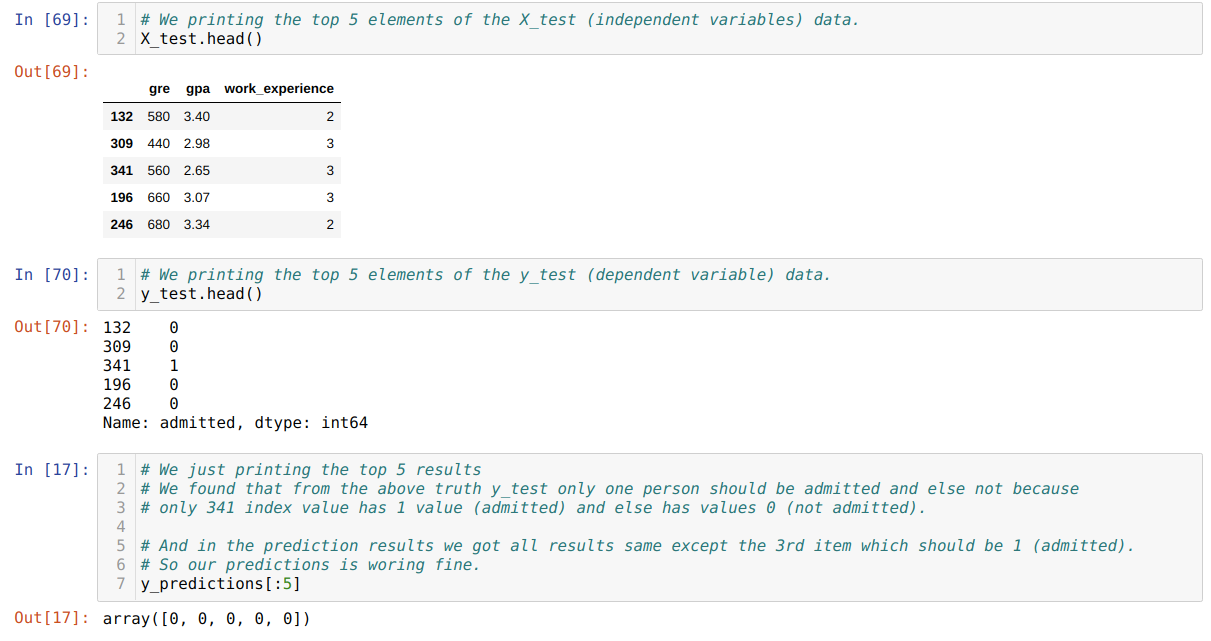
Nous combinons les trois résultats dans une feuille pour comprendre les prédictions comme indiqué ci-dessous. Nous pouvons voir qu’à l’exception des 341 données X_test, qui étaient vraies (1), la prédiction est fausse (0) sinon. Ainsi, nos prédictions de modèle fonctionnent à 69%, comme nous l’avons déjà montré ci-dessus.
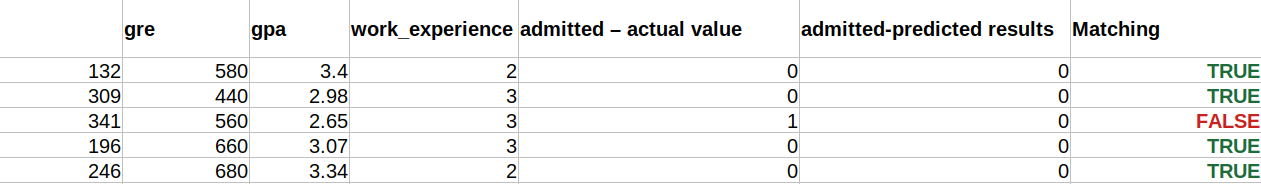
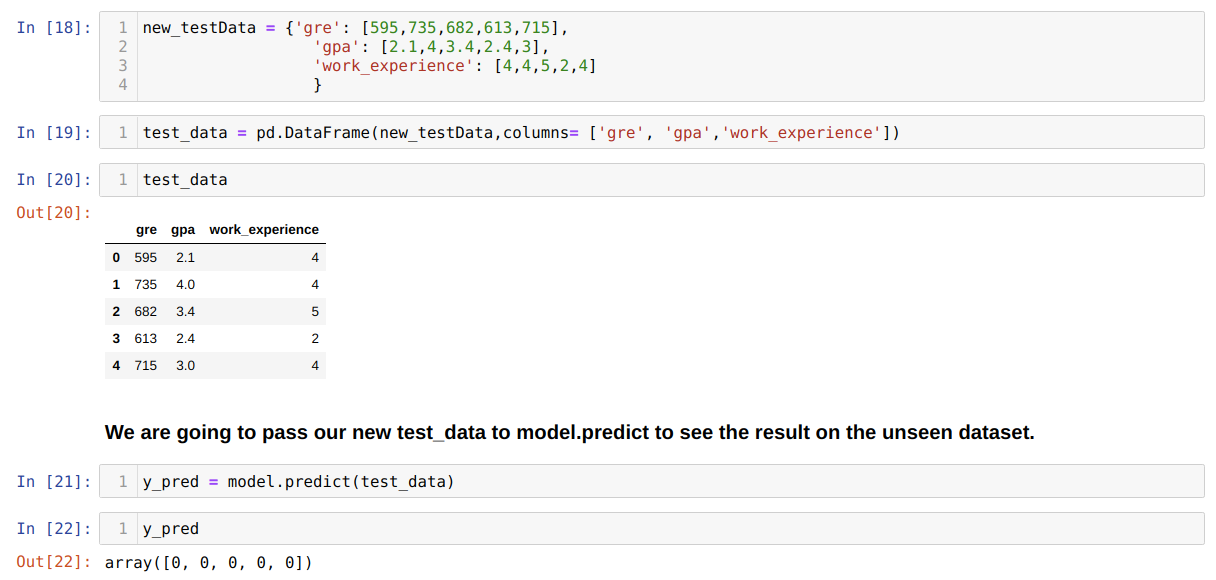
Étape 11: Nous comprenons donc comment les prédictions du modèle sont effectuées sur l’ensemble de données invisible comme X_test. Ainsi, nous avons créé juste un nouvel ensemble de données au hasard à l’aide d’un dataframe pandas, l’avons passé au modèle entraîné et obtenu le résultat ci-dessous.
Le code complet en python donné ci-dessous: